Propensity models are a hot topic and with good reason. In tech and development circles, propensity models are being held up as the answer to almost every challenge, but the truth is that a lot of the people who talk about them don’t really know what they’re talking about.
But we can’t blame them because propensity models can be challenging to wrap your head around, and they have such a vast amount of potential that we’re still learning the true extent of their capabilities as an industry.
And that brings us to the question we’re going to answer today – what exactly is a propensity model? And what do you need to know about them? So let’s take a closer look and get some answers.
What is a propensity model?
A predictive propensity model is a form of statistical analysis which aims to predict the future actions of a pre-determined set of people.
For example, in the marketing industry, people typically use predictive propensity models to get to know their target audience and understand how they will react to any given situation.
To determine this, they need access to a large amount of good quality data that typically includes behavioral data and key information like their demographics and interests.
Done well, you can then use the insights that the propensity model provides you to better cater to these audiences and increase your chances of generating further revenue from them.
It’s impossible to know the future with any certainty, but propensity models provide you with the closest you can get to proper knowledge.
It’s similar to how sports teams use data to determine how their opponents are likely to react during a game. For example, football teams in the English Premier League use modeling to determine how players are likely to take a penalty so that they can coach their goalkeepers on which way to jump.
It’s been said that data is the new oil, but that’s only true when you know how to process it and put it to good use.
Propensity models are arguably the best way to process that data.
How do marketers use propensity models?
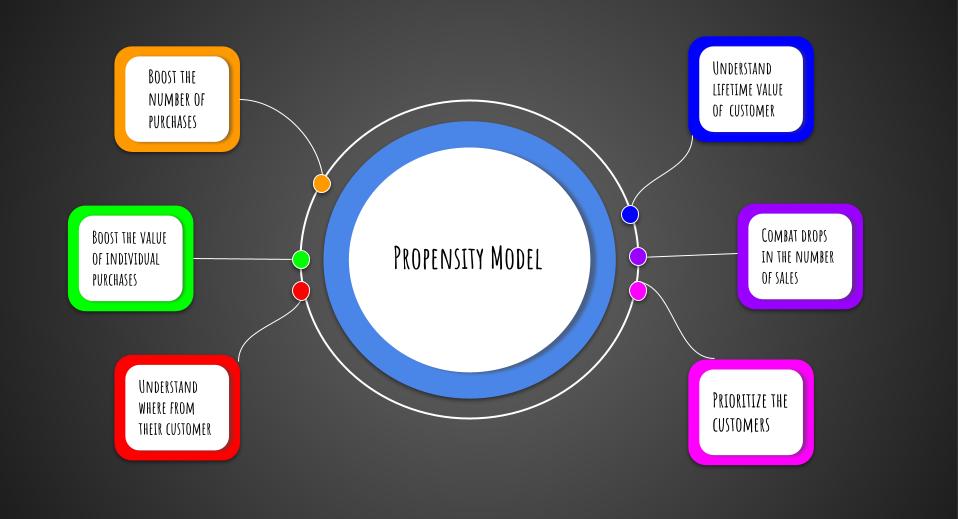
When marketers use propensity models, it’s generally to take the data and the models they create to influence consumer behavior.
Then, they’ll typically try to make changes to their marketing based upon the propensity models to:
- Boost the number of purchases
- Boost the value of individual purchases
- Understand where their customers are coming from
- Combat drops in the number of sales
- Understand the lifetime value of any given customer
- Prioritize the customers who are likely to spend the most
Because propensity modeling allows you to understand better the triggers that cause people to act, shrewd marketers can tap into this understanding to cause more of those triggers.
It doesn’t mean that you’re changing their mind and making them do things they don’t want to do, but rather that you’re helping them make up their minds.
Types of propensity models
There are as many different propensity models as there are different developers. So if you’re looking into developing a predictive model, you need to make sure that you know what kind of model you want and what you hope it will achieve.
As with most things marketing-related, it’s all about defining your goals, identifying the best way to measure your predictive lead scoring, and then taking action. Let’s look at a few of the most common goals for propensity models.
Propensity model to purchase or convert
Perhaps the most obvious use for propensity models is to model people’s likelihood of converting either into a paying customer for B2C companies or a lead for B2B companies. These propensity models are usually the easiest ones to tie a return on investment (ROI) to, so they’re also a popular choice amongst marketers.
Propensity model to calculate customer lifetime value (CLV)
The next step up from optimizing for purchases and conversions is to optimize for customer lifetime value (CLV). This comes into play when a company repeatedly makes multiple sales to the same customers.
Creating a propensity model for purchases and conversions only focuses on the short term rather than the long term. The customers who will spend the most over their lifetime usually differ from those who are most likely to make an immediate purchase.
Deciding between this and the previous model comes down to what you’re hoping to achieve and the timeframe you’re looking to do it in. You can also consult with Customer Success experts to gain valuable insights and recommendations tailored to your specific goals.
Propensity model to churn
Customers who churn are those who leave your company and go elsewhere to buy a replacement product/service or go without altogether.
The goal of creating a propensity model to identify people likely to churn is to find ways to keep them as customers, typically by upselling or adding some additional value to any transactions they make.
Some marketers also use vouchers, discounts, and other special offers to keep people as customers.
Propensity model to engage
A propensity model built around engagement is about trying to increase the amount of engagement that customers have with your brand and the content it’s creating.
Engagement is generally a lower priority than other metrics, but it can still be an important and useful vanity metric for social networking sites and marketing campaigns.
Qualities of a proper propensity model
Now that we know a little more about the different types of propensity models that are out there, it’s time to take a look at what separates the good ones from the bad. First, let’s investigate what a proper propensity model looks like.
Productionized
A productionized propensity model is able to be deployed in a live environment. The big challenge with propensity models is to build one that works in a real-world environment and with real-world data.
For a productionized propensity model to work, it needs to be designed with real-world applications in mind from the outset. It’s more difficult to do this, but it’s also a no-brainer. What’s the use of a model that doesn’t actually have any value?
Dynamic
For a propensity model to be dynamic, it needs to be able to change whenever new data becomes available. Technologies like machine learning can often help with this.
The idea is that as new data comes in, the propensity model can update itself and evolve. This will help to ensure the accuracy of its predictions even in an ever-changing landscape, as well as increase the accuracy of any given prediction.
That’s because more data almost always means greater accuracy.
Scalable
This point builds upon the last one because the more data comes in, the more your model will need to scale upwards to process that data.
The biggest mistake we see with propensity models is that people will build them for a single-use campaign, and then once that campaign is over, they’ll abandon the models.
Instead, it’s better to design the model to be scaled upwards right from the outset so that it can be used again and again instead of as a one-time-only thing.
Demonstrate ROI
Return on investment (or ROI) is the holy grail of all marketing, and the same is true of propensity models. Even if you’re pretty sure that your propensity model is paying for itself, it’s not enough to rely on gut feeling.
Instead, it would be best if you built ROI calculations into your model right from the outset so that as well as hopefully paying for itself, it can also prove that it’s doing so.
How to implement propensity modeling with machine learning?
Machine learning (ML) and propensity modeling are a match made in heaven because ML is a subgenre of artificial intelligence that’s specifically designed to process large amounts of data and draw conclusions from it.
That sounds to us like exactly how propensity modeling works.
In fact, ML algorithms and predictive propensity modeling are all around us, even if we’re unaware of them. For example, Netflix’s recommendations algorithm uses machine learning and propensity modeling to predict their users’ viewing behavior.
Their goal is to serve up suggestions that will keep them on the site for as long as possible.
Mapping out a strategy
As with everything that you do as a part of your approach to marketing, there needs to be a strategy in place before you get started.
Now that you know the different types of propensity models, you should have a good idea of the kind of model that you’re interested in making. It would help if you also had a good idea of what a proper propensity model looks like.
Now it’s time for you to start working on mapping out a strategy, and that’s where it can be worth getting a little help. If you’ve never built a propensity model before, you may want to find an agency that you can partner with.
Collecting and preparing relevant data
The data that you feed into your propensity model is the most important piece of the jigsaw puzzle. After all, if you don’t get the inputs right, you’re not going to get the outputs right, either.
At the same time, though, we live in a world in which we’re constantly overwhelmed by data, and so it can be difficult to figure out which data is the right data to give to the machine.
As well as identifying the relevant data and finding the best way to collect it, it also needs to be prepared in such a way that the algorithm can understand it. This can often mean cleaning up the data and ensuring that it’s all tagged correctly.
Create and test a model
The next step is for you to create a model and start testing it. The goal during the testing phase should be to look for bugs and to see whether the data that it’s providing is actually useful.
You’d be surprised how often people forget to check that they’re actually going to be able to use the data that the model provides.
One of the best ways to test your model is to hand it over to your team and tell them to go nuts. After all, they’re the people who are actually going to be using it, and so they’re the best people to judge whether it’s getting the job done.
They’ll also be able to find bugs that your developers would never find just by virtue of not thinking like a developer.
Deploying a propensity model
Once you’ve finished developing your propensity model, you’re ready to deploy it. The key to a successful deployment is to make sure that people know that it’s coming and to maintain communication throughout the process because otherwise, you’ll successfully deploy the model, but no one will use it.
You’re also going to want to make sure that you provide plenty of support, both in terms of help centers and tutorials and in terms of providing ongoing support between the model’s developers and the people who are picking it up as end users.
You should also bear in mind that just because the model has been deployed, it doesn’t mean that you can’t make further changes.
Propensity modeling use cases
To get a fuller understanding of how propensity modeling works in the real world, it can help to take a look at a few real-life case studies. Luckily, we’ve got you covered. Here are three mini-case studies that show how propensity modeling can be used in the wild.
Use Case #1

Former US President Barack Obama relied heavily on propensity modeling as part of his successful 2012 re-election campaign.
There are no guarantees when it comes to politics, but propensity modeling can at least increase the chances of success.
Obama’s team hired a bunch of data scientists to build propensity-to-convert models that could predict which undecided voters could be persuaded to vote for the democrats. They were also able to figure out which medium would be most successful, such as calling people versus knocking on their door or sending them an email.
Use Case #2
Scandinavian Airlines (SAS) uses a propensity model powered by machine learning to analyze customer behavior at a huge scale. Their goal is to provide customized offers to every individual client, thus increasing sales and improving engagement and retention.
This personalized approach is reminiscent of how different types of quizzes can tailor content to individual preferences and needs, enhancing the overall customer experience.
This is an interesting use case of propensity modeling because it shows how it can be coupled with personalization to provide a truly tailored experience to every customer, regardless of how much they’ve spent or how many times they’ve flown.
Use Case #3
The UK’s largest tool supplier uses sales propensity modeling to identify which customers have higher revenue potentials than is suggested by their current spending. They can then prioritize these leads when following up with their sales teams.
They created a sales propensity model that scraped data from Companies House and other third parties to enrich their own data and made it a priority to create a tool that their sales teams could understand. They were able to tag 30,000 accounts with higher potential for their sales teams to follow up with.
Wrapping up
Now that you know more about propensity models and how they work, we want to hear from you.
Of course, if you need a little more help and you’re in the market for an agency, we’ll be happy to help. Get in touch with us today to learn more about how we can help you to build a propensity model.