

If you’ve been thinking about machine learning in the last couple of years, you’re not the only one.
It’s big business and can have a significant impact on the way that companies perform, providing a much-needed competitive advantage.
The statistics bear that out. For example, the global ML market is expected to be worth over $115 billion by 2027, while AI and ML advancements are set to increase global GDP by 14% from 2019 to 2030.
In addition, Netflix says it’s been able to save $1 billion by using machine learning.
And so now that we know why ML is essential let’s take a quick refresher on what exactly machine learning is before we move on to the seven steps of the ML life cycle.
What is Machine Learning?
Machine learning is a subset of artificial intelligence that aims to mimic how human beings learn by using data, algorithms, and AI to slowly improve accuracy over time.
For example, Netflix uses machine learning to power its recommendations algorithm, taking the enormous amounts of viewing data that it has access to and crunching the numbers to show people what other similar users have enjoyed.
For machine learning to work, you need a strong model and access to a large amount of data.
Most ML algorithms also have access to a floodgate of incoming information, and they can get better and better at what they do as more and more data comes in.
Machine learning has a massive number of potential applications, from providing personalized healthcare to powering self-driving cars and smarter cities.
In fact, machine learning has applications in every industry out there, so the question isn’t whether your company can benefit from it but rather whether it can be the first in your niche to do so.
The Seven Steps of the Machine Learning Life Cycle
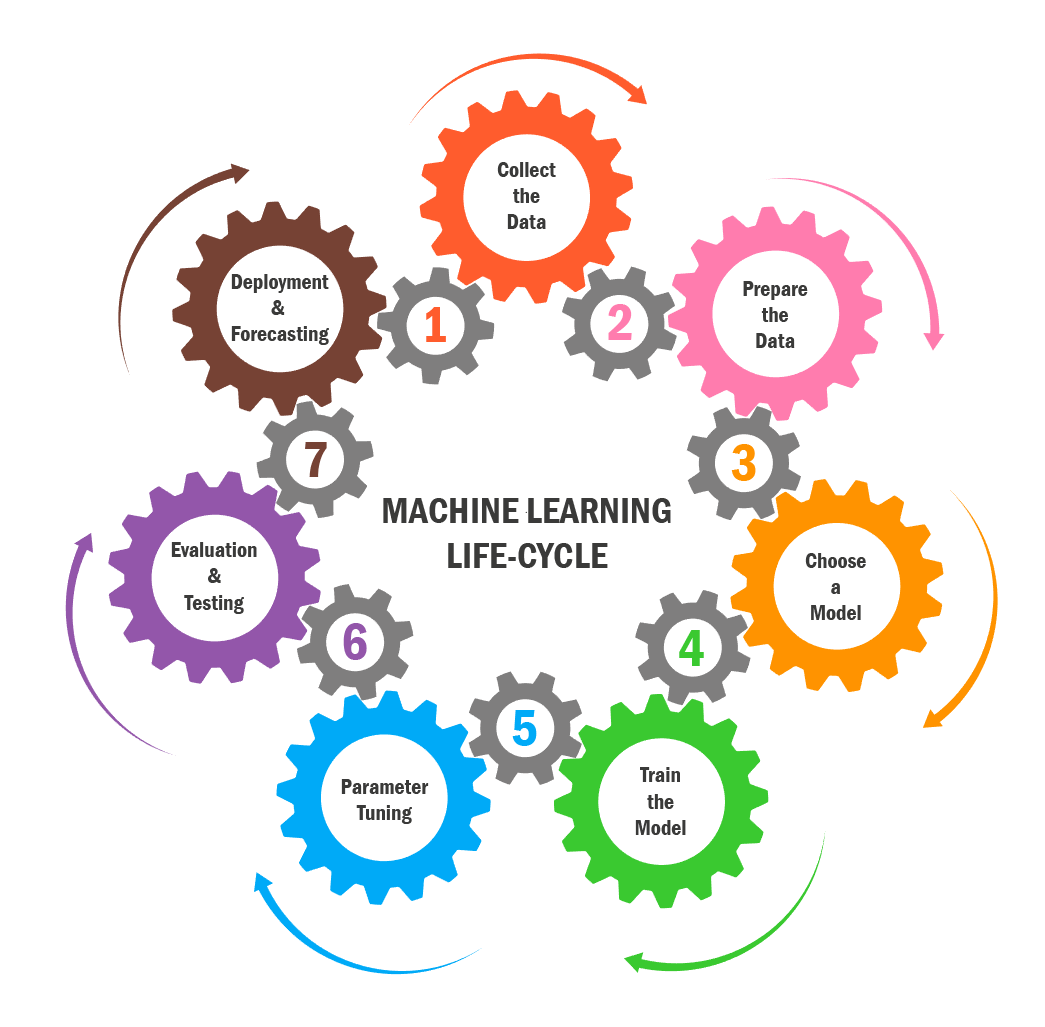
Now it’s time for us to take a little look at the machine learning life cycle.
There are seven steps to this, and the first couple is the most intense, so stick with it until the end.
Collect the Data
The first step in any ML campaign is to start collecting data. After all, if you don’t have any data, your machine-learning model won’t have anything to process.
We can split data collection up into three further stages.
Identify Data Sources
Before you can start to collect any data, you need to know where you’re going to get that data from.
Depending upon the type of model that you’re building, you may find yourself using your own proprietary data, accessing public data (such as via a social networking site), or a mixture of both.
It’s also worth considering whether you want explicit data (people specifically provide that) or implicit data (that’s identified based on people’s browsing habits and activity).
Gather Data
Now that you know what your data sources are going to be and the kind of data that you’re looking to capture, the next step is for you to start gathering data.
You’ll need to make sure that you’re gathering the right data from the right source, which is where the previous step comes in. Don’t worry about tidying up the data yet because that comes a little later.
Integrate Data
This next step is to integrate the data that you’ve gathered with your workflow and, ultimately, your machine learning model.
This may mean importing the data into your proprietary database or using APIs to set up an automated feed of data from third-party sources.
Preparing the Data
Now that you’ve identified your data sources, gathered them, and integrated them into your system, the next step is for you to prepare it so that the model is ready to start using it. There are four steps to this process.
Data Exploration
First up, you need to take a look at the data that you have so that you can get a feel for how complete it is and how much work is going to be needed to make it suitable for your uses.
This is also where you’ll identify the approach that you’ll take during the next two steps to make sure that you have everything ready for the algorithm.
Data Pre-Processing
Pre-processing involves cleaning up any formatting that might be in place and stripping out blank entries and other anomalous elements within the data.
We’re talking about actions that you can carry out across the whole dataset to make it ready for further processing rather than focusing on any individual entries.
Data Wrangling
With that out of the way, you’re now ready to tackle individual records. Data wrangling requires you to manually go through the data that you have and to update any of them that need updating for your company to be able to process it.
This is also where you’ll carry out any changes to the data that are needed to make it readable and easy to process for the model that you build.
Analyse Data
By now, your data should be in pretty good shape, so the next step is for you to take a closer look at the data that you have and analyze it to determine how you’re going to go about processing it and building your model.
Choose a Model
Now that we’ve sorted out your data and taken a good look at what you have, the next step is for you to choose a model so that you can start to process that data and work towards your end goal.
There are a number of different options out there when it comes to choosing your model, so the best bet is to do some research into what’s out there and to find a developer who’s able to best advise you on what you need. We can help with that!
Train the Model
Now that you’ve chosen your model, the next step is to start developing it and feed it the data that you have so you can begin to train it.
When we talk about training a model, that’s because machine learning algorithms work by teaching themselves.
Instead of telling them what dogs and cats look like, you provide them with a bunch of labeled data on dogs and cats and then train the model to come to its own conclusions.
Model Evaluation and Testing
Once your model has trained itself based on the data that you’ve given it, you’re ready to start testing it and evaluate whether it’s achieving the goals that you’ve set for it.
Testing and evaluation go hand in hand because testing will be a key part of your evaluation and will help you to determine whether the thing is working. After your testing, you’re ready to move on to the next step.
Model Parameter Tuning
With testing and evaluation out of the way, you should now have a good idea of what changes you need to make to your model to fine-tune it and ensure that it does a better job of taking you toward your goals.
You can repeat steps five and six over and over again, one after the other, until you’re ready to move on to the seventh and final step.
Model Deployment and Forecasting
Now that you’ve completed your evaluation, testing, and fine-tuning, your model is ready for live deployment.
Once you’ve deployed it, you’re prepared to start forecasting and making predictions using the data that you have access to, and you’ll be able to make decisions accordingly. And to streamline this process, consider utilizing a virtual data room for efficient data management and collaboration.
You can also always go back and carry out more fine-tuning or add new data sources, so don’t think that the build is over and done with just because it’s live.
If there’s one thing machine learning shows us, there’s always room for improvement.
Conclusion
Now that you know how to get started with machine learning, you’re in the perfect place to take things to the next step by implementing machine learning at your company.
The good news is that if you still need a little help, we’re more than happy to help.
Here at Zfort Group, we have a vast amount of experience in working with machine learning models, and we’ve successfully delivered projects for companies of all sizes across a range of different industries.
And so, if you’re ready to get started with machine learning but you don’t know where to begin, we’ve got you covered.
Reach out to us today to find out more about how we can help you. We’ll see you soon for another article!



